Haar-like features 는 Haar function 이 mother wavlet 을 이용해 값을 결정하는 것처럼 작은 feature들을 이용해 값을 결정짓게 하는 영상정보처리에 있어서의 기법 중 하나다.
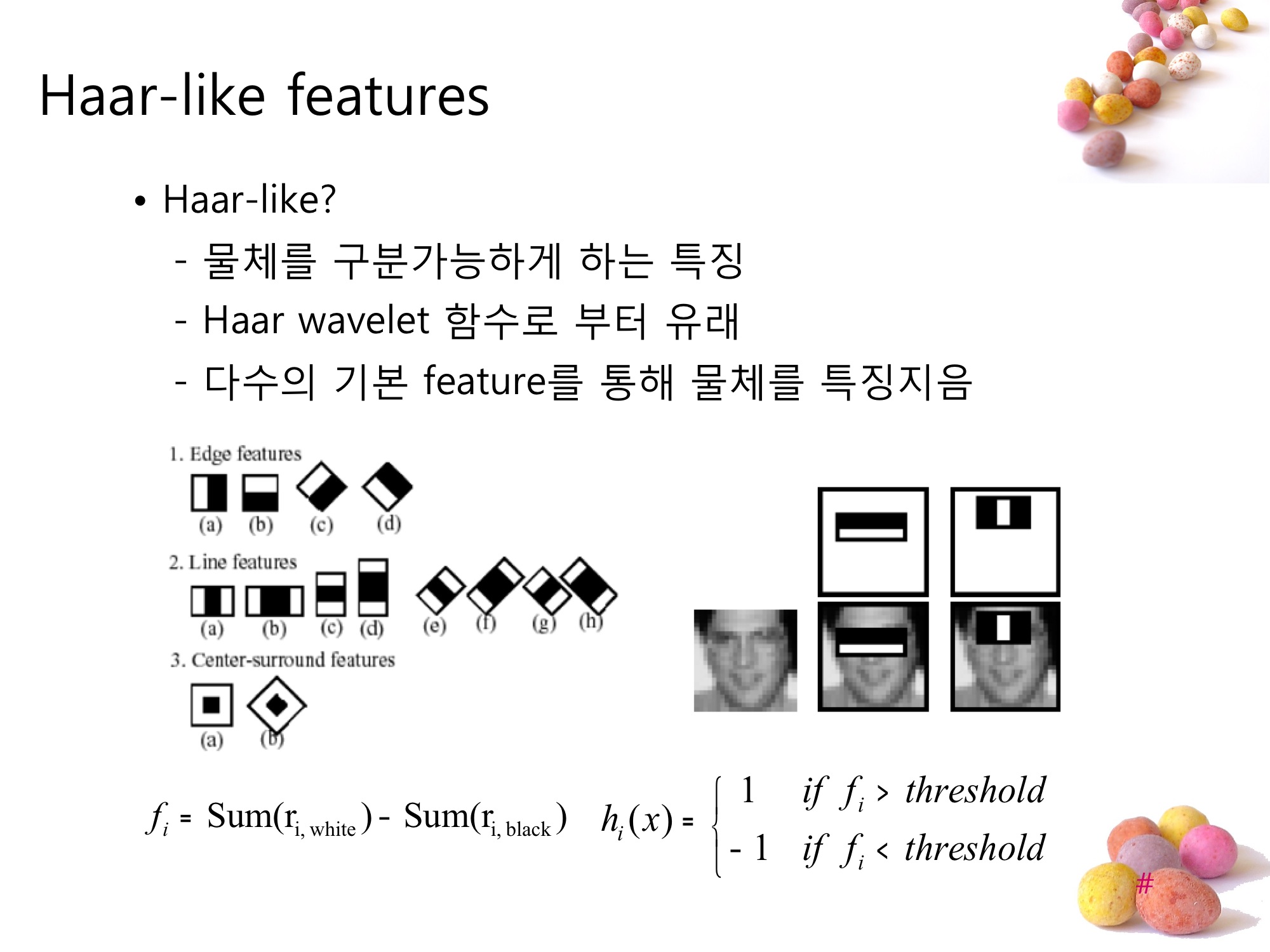
OpenCV에서 Object detection을 하기 위해서는 feature_cascade.xml이라는 정보 파일을 haartraining이라는 프로그램을 이용해서 만들어야하는데, 여기서 사용되는 ‘이미지 판별’의 기본 단위가 바로 Haar-like features 다.
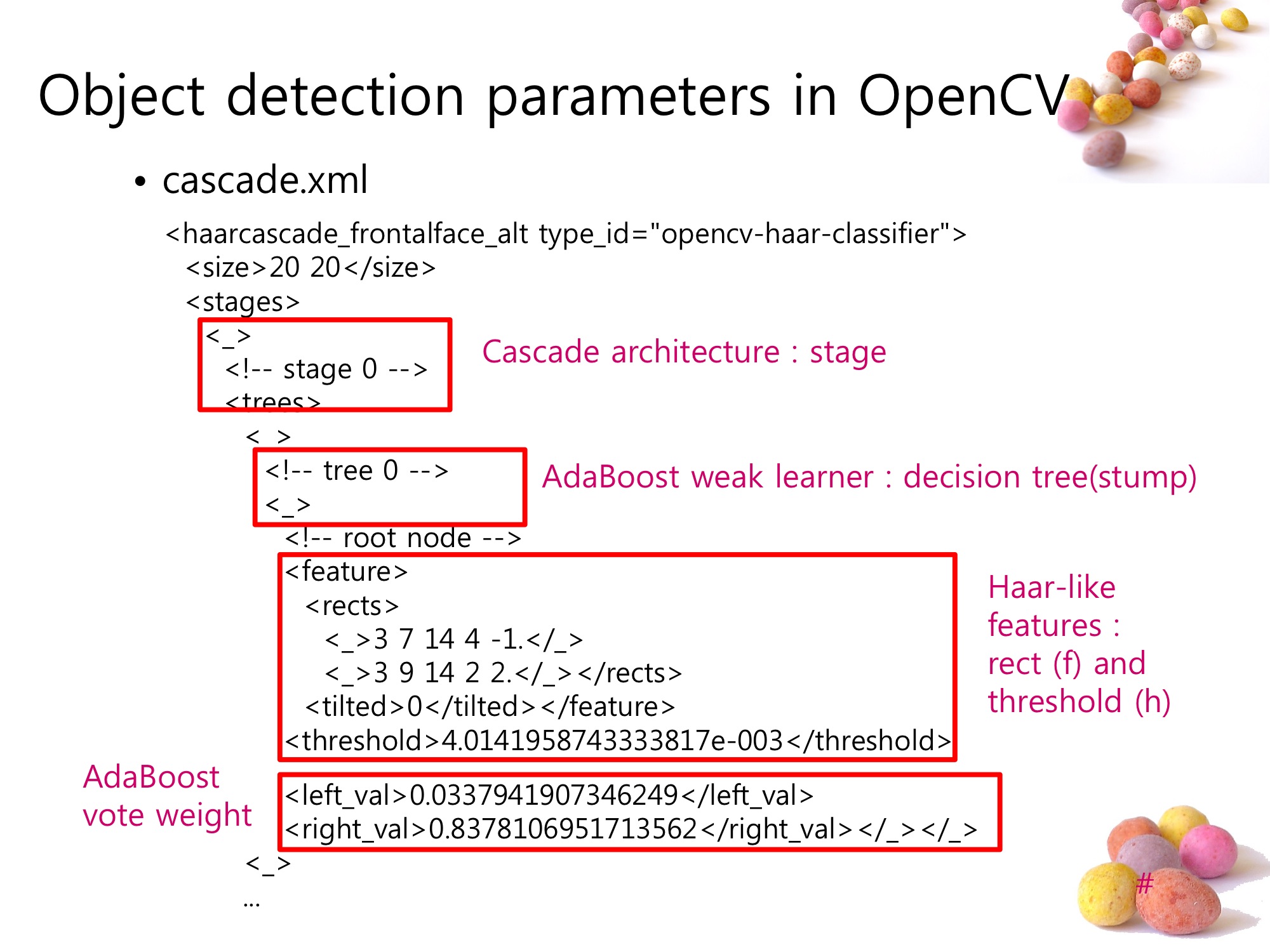
OpenCV에서는 weak learner들로 연결된 여러 AdaBoost stage를 ‘cascading’ 하여 사용한다. 이 Cascade Architecture는 ‘아닌것은 빨리 걸러내는’ 목적으로 설계되어 있다.
하나의 weak learner(classifier)는 Decision tree로 구성되어 있으며, Haar-like feature의 부합정도를 ‘node bursting factor’로 사용한다.
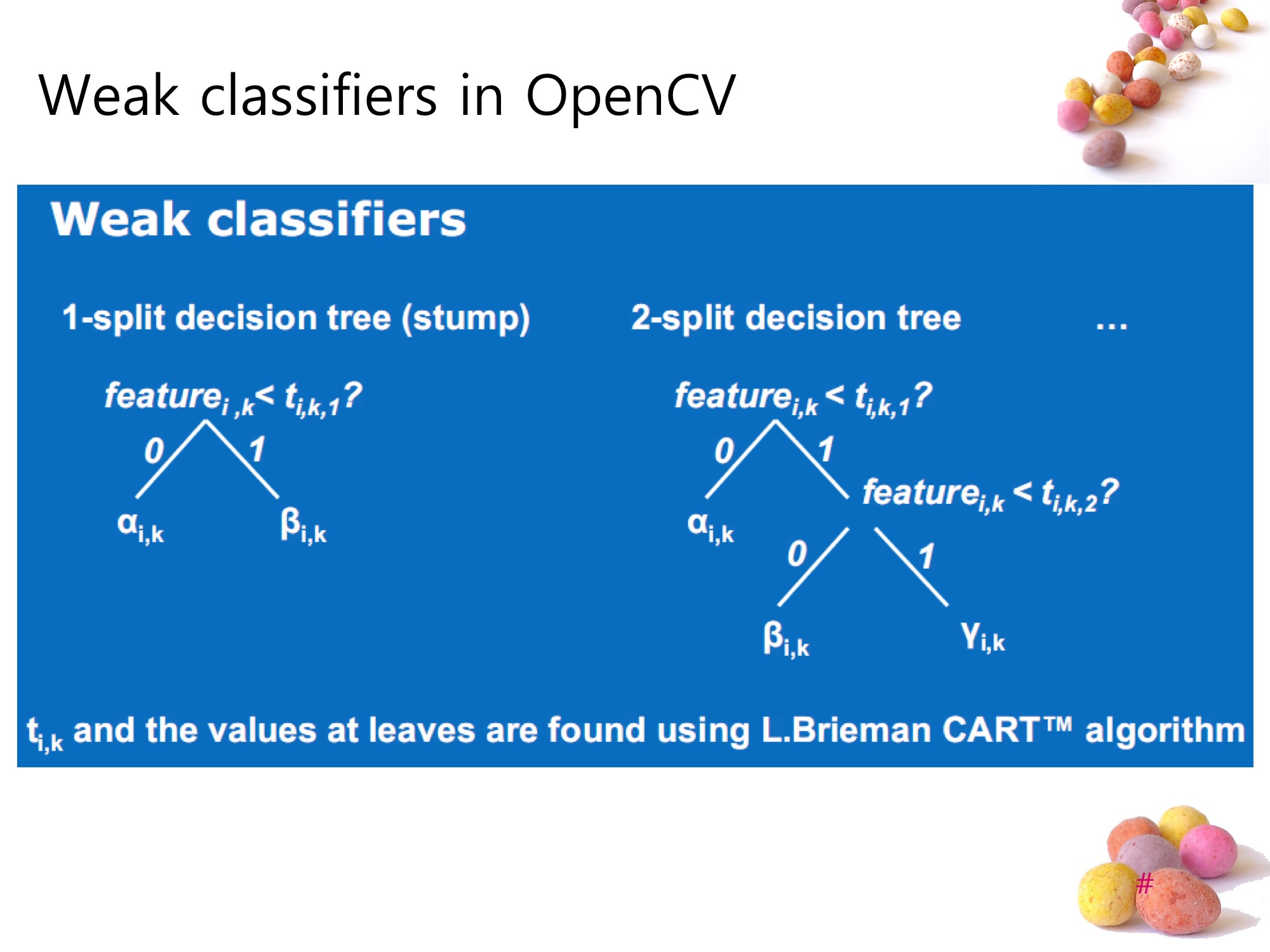
Decision tree를 만들어내는 방법에는 여러가지가 있다. 기본적인 decision tree induction process로부터 ID3, CART등의 방법이 있는데, OpenCV에는 CART를 사용한다. 그리고 decision tree의 split selection method에는 엔트로피를 이용한 ‘Information theory’를 사용한다.

실제적인 haartraing 프로그램의 옵션에는 어떤 종류의 haar-like feature들을 사용하고 어떤 AdaBoost 알고리듬을 적용할 것인지도 설정할 수 있다. 그래서 준비된 positive 샘플과 negative 샘플, 그리고 사용할 알고리듬을 결정하여 프로그램을 실행해 feature_casecade.xml을 만든다. 시간이 매우 오래 걸리는 점을 주의할 것.

OpenCV에서는 AdaBoost 알고리듬들중 GAB를 기본 알고리듬으로 사용한다. 일반적인 DAB 와 큰 차이는 없지만 regression fuction을 이용한다는 차이점이 있다.

앞으로 더 해보고 싶은것들 :
- decision tree에서 information theory 공부. (AI 수업교재였던 Luger의 AI책에 내용이 좀 있다.)
- 일반적인 파라미터의 CART 알고리듬 구현
- AdaBoost의 일반적인 구현
졸업 프로젝트로 했던 Face gesture recognition의 PT를 활용했는데, 개인적인 사진이 실려있는 부분을 제외한 대부분의 내용을 구글닥스에 올렸으니 관심있으신 분은 참고하시길.